今天讲讲用爬虫下载万方数据库文献。
这是我们要爬取的文献链接:
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zgtx201803009

右键那个下载按钮 -> 检查,我们可以看见,按钮的点击事件是一个 js 函数 upload() 。

在网页源代码中,寻找这个 upload() 函数,发现它只在按钮处出现了一次。所以,这个函数应该是由 js 文件加载的。
在网页源代码中,寻找 .js(搜索 js 文件),点击每一个 js 文件的链接,看看里面有没有 upload() 函数(这个方法貌似有点蠢,不知有没有更高效的方法)。最后在下图这个文件找到了:
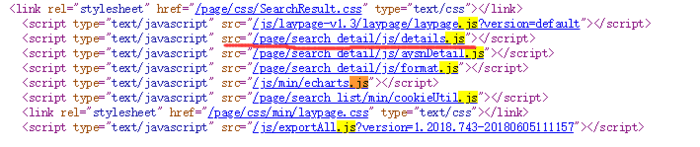
upload() 函数代码如下:1
2
3
4
5
6
7
8function onlineReading(page_cnt,id,language,source_db,title,isoa,type,resourceType){
title=window.encodeURI(window.encodeURI(title));
var type = $("#document_type").val();
if(type == "standards"){
type="standard";
}
window.open("/search/onlineread.do?page_cnt="+page_cnt+"&language="+language+"&resourceType="+type+"&source="+source_db+"&resourceId="+id+"&resourceTitle="+title+"&isoa="+isoa+"&type="+type);
}
可以看到,这个函数构造了一个 url, 并在一个新的标签页打开了这个 url。
把参数填进去,构造出的 url 为
1 | http://www.wanfangdata.com.cn/search/downLoad.do?page_cnt=16&language=eng&resourceType=perio&source=WF&resourceId=zgtx201803009&resourceTitle=Spectral Efficiency and Power Allocation for Mixed-ADC Massive MIMO System&isoa=0&type=perio |
在浏览器中访问该 url ,发现我们看到的网址,并不是我们构造出的请求 url,说明应该是发生了重定向。
在一个新标签页中,按 F12 监听请求,并打开我们的请求 url
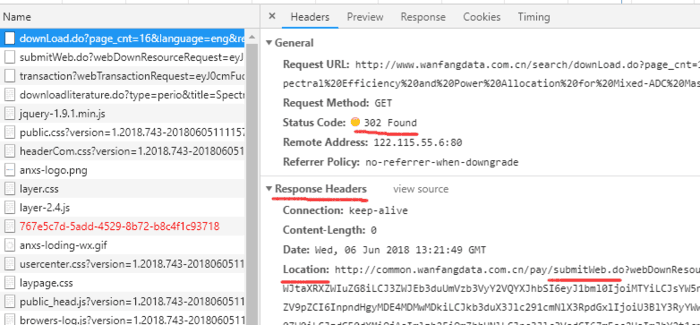
可以看到,我们构造的 url(也就是 downLoad.do? ),重定向到了 submitWeb.do? 。点击 submitWeb.do ,我们可以看到它重定向到了 transaction?,最后才重定向到 downloadliterature.do?
写爬虫时,我们要确保能够到达 downliterature.do?,后面才能下载文件。所以我们先写程序看看能不能提取出这个 downloadliterature.do? 的详细 url。
首先是用正则表达式提取 upload() 函数的参数,然后构造出请求 url,这里我懒得写了,直接 copy 一下:
1 | url = 'http://www.wanfangdata.com.cn/search/downLoad.do?page_cnt=16&language=eng&resourceType=perio&source=WF&resourceId=zgtx201803009&resourceTitle=Spectral Efficiency and Power Allocation for Mixed-ADC Massive MIMO System&isoa=0&type=perio' |
接着发起请求:
1 | import requests |
运行结果如下:
1 | 200 |
还是挺顺利的,一下子就得到了 downloadliterature.do? 的详细 url。这里解释一下:默认情况下,除了 requests.head() 方法,requests 会自动帮我们处理所有重定向。而 response.url 就会返回初始请求重定向后的最终网址。(差点忘了说了,我是用的学校网络,所以能免登陆下载。)
将得到的网址复制到浏览器中打开,会出现一个网页,再弹出下载对话框。这说明,downloadliterature.do? 并不是文件的最终下载链接,如果是文件的最终下载链接的话,就应该会直接弹出对话框。所以,我们的下一步就是找出真正的下载链接。
观察 downloadliterature.do? 网页:
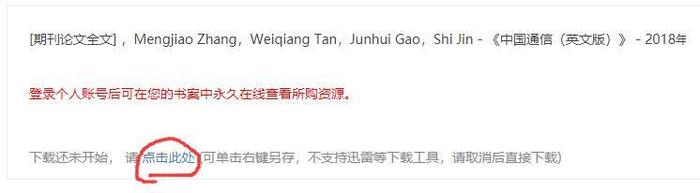
这里有个点击下载的地方,通过 F12 以及查看网页源代码,我们可以看到文件的真正下载链接。接着,我们用正则表达式提取该链接,然后就可以用 requests 下载文件了。
最后,总结一下这一次寻找下载链接的思路:
- F12 检查
下载按钮元素,发现,点击后触发的是一个 js 函数upload()。- 在网页源代码中找不到
upload()的实现,转而在网页包含的 js 文件中找。- 找到
upload()后,根据其实现,构造请求 url。- 在浏览器中打开请求 url,发现网页重定向了。用 requests 和 response 获取重定向后的 url
- 得到重定向的 url 后,打开,并提取其中包含的文件下载链接